GAN(Generative Adversarial Networks, 생성적 적대 신경망)은 2014년 Ian Goodfellow가 제안한 딥러닝 모델로, 새로운 데이터를 생성하는 능력을 가진 신경망입니다.
GAN의 핵심 개념은 "적대적 학습(Adversarial Training)" 으로, 두 개의 신경망이 서로 경쟁하며 학습합니다.
이번 포스팅에서는 GAN의 구조와 작동원리에 대해 알아보겠습니다.
Generative Modeling
GAN에 대해 본격적으로 들어가기 전에, generative modeling(생성 모델링) 개념에 대해 먼저 짚고 넘어가보자.
Generative Modeling이란, 가지고 있는 데이터 분포에서 sampling한 것 같은 새로운 데이터를 만드는 것을 의미한다.
생성 모델링과 반대되는 개념인 판별 모델링과 비교하여 살펴보자.
- 판별모델링 : Sample x가 주어졌을 때, label y의 확률 P(y∣x)를 추정
- label y가 필요한 supervised learning
- 생성모델링 : Sample x의 P(x)를 추정
- label y가 필요 없는 unsupervised learning
생성모델링의 목적 : Want to learn Pmodel(x) similar to Pdata(x)

GAN의 구조
새로운 데이터를 생성하기 위해 뉴럴 네트워크로 이루어진 생성자(Generator)와 판별자(Discriminator)가 서로 경쟁하며 훈련
| 생성자 Generator | 판별자 Discriminator | |
| 입력 | 랜덤한 숫자로 구성된 벡터 z | 1. 훈련 데이터셋에 있는 실제 샘플 x 2. 생성자가 만든 가짜 샘플 z |
| 출력 | 최대한 진짜 같이 보이는 가짜 샘플 G(z) | 입력 샘플이 진짜일 예측 확률 |
| 목표 | 훈련 데이터셋에 있는 샘플 x와 구별이 불가능한 가짜 샘플 G(z) 생성하기 | 생성자가 만든 가짜 샘플 G(z)와 훈련 데이터셋의 진짜 샘플 x 구별하기 |
GAN의 Loss
Loss 함수 공식
GAN의 판별자 D는 real or fake를 판단하기 때문에, Binary Cross Entropy(이하BCE)를 사용
- real일 때 y = 1, fake일 때 y = 0인 이진분류
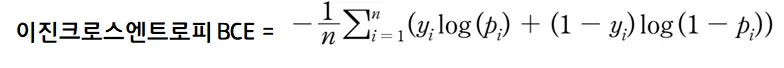
여기서 파생되어 나온 식이 바로 아래에 있는 GAN의 Loss Function입니다.
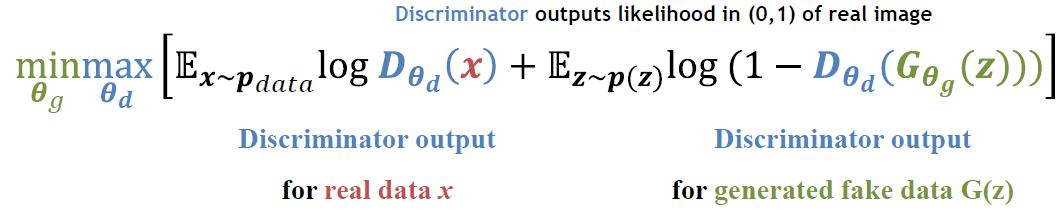
- x~P_data(x) : 실제 데이터 분포에서 온 sample x
- z~P_z(z) : Gaussian 분포(예)에서 온 Sample latent code z
D와 G의 목표
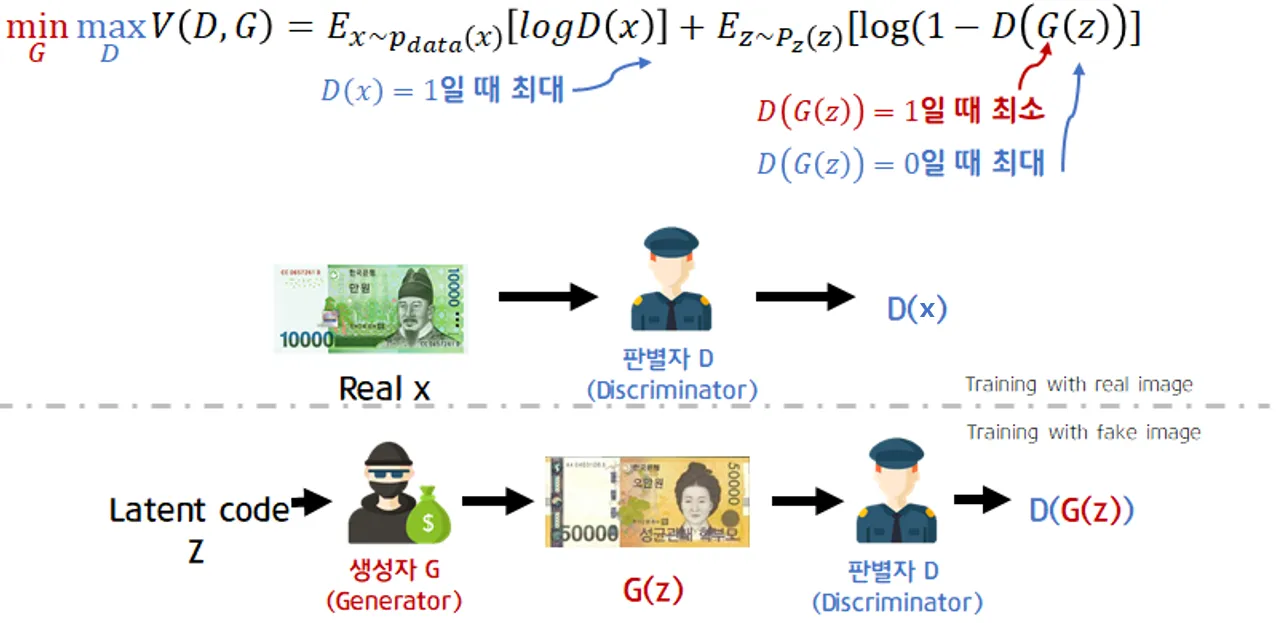
- 판별자 D의 목표 : loss를 최대화 하는 것
- 생성자 G의 목표 : loss를 최소화 하는 것
- 생성자의 입력은 x와 관련 없기 때문에, Ex~Pdata(x)[logD(x)]항은 고려하지 않음
이제 차근차근 D와 G의 입장에서 하나씩 살펴봅시다.
1. (D의 입장에서) value function V(D,G)의 이상적인 결과
D가 매우 뛰어난 성능으로 판별을 잘 해낸다고 했을 때,
- D가 판별하려는 데이터가 실제 데이터에서 온 샘플일 경우
→ D(x)=1
→ 첫 번째 항은 0이 되어 사라짐 - G(z)가 생성해낸 가짜 이미지를 구별해낼 수 있음
→ D(G(z))=0
→ 두 번째 항은 log(1-0)=log1=0
→ V(D,G) = 0 - 즉 D의 입장에서 얻을 수 있는 이상적인 결과, '최댓값'은 '0'
2. (G의 입장에서) value function V(D,G)의 이상적인 결과
G가 D가 구별 못 할만큼 진짜와 같은 데이터를 잘 생성해낸다고 했을 때,
- 첫 번째 항은 D가 구별해내는 것에 대한 항으로 G의 성능에 의해 결정될 수 있는 항이 아니므로 무시
- 두 번째 항에서는 D가 G가 생성해낸 이미지를 가짜라고 인식하지 못하고 진짜라고 결정내버림
→ D(G(z)) =1
→ log(1-1) = log0 = -∞ - 즉, G의 입장에서 얻을 수 있는 이상적인 결과, '최솟값'은 '-∞'
🌟요약🌟
1. D는 training data의 sample과 G의 sample에 진짜인지 가짜인지 올바른 라벨을 지정할 확률을 최대화하기 위해 학습 (V(D,G) 최대화)
2. G는 log(1-D(G(z))를 최소화(D(G(z))를 최대화)하기 위해 학습 (V(D,G) 최소화)
GAN의 학습 과정
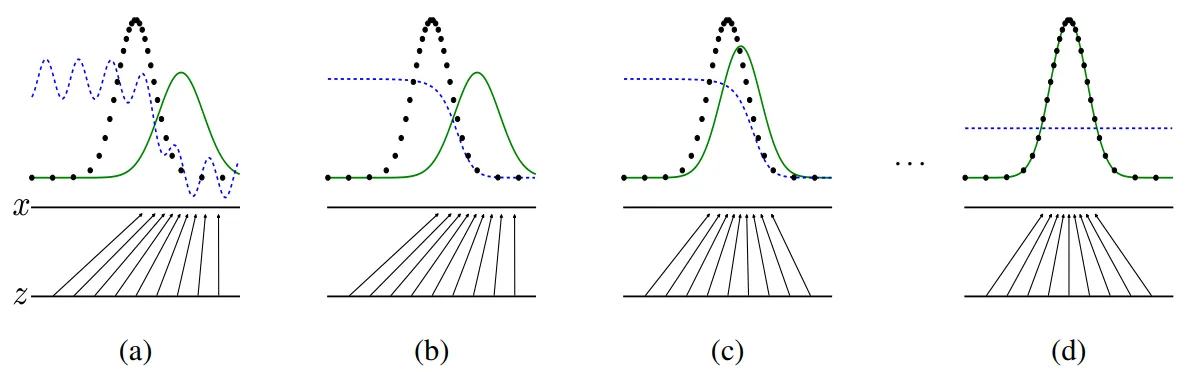
파란색 점선 : discriminative distribution
검은색 점선 : data generating distribution(real)
녹색 실선 : generative distribution(fake)
(a) 학습초기에는 real과 fake의 분포가 전혀 다릅니다. D의 성능도 들쑥날쑥한 것으로 보아 썩 좋지 않아 보입니다.
(b) D가 (a)처럼 들쑥날쑥하게 확률을 판단하지 않고, 흔들리지 않고 real과 fake를 분명하게 판별해내고 있습니다. 이는 D의 성능이 올라갔음을 의미한다고 볼 수 있겠네요.
(c) 어느 정도 D가 학습이 이루어지면, G는 실제 데이터의 분포를 따라가며 D가 구별하기 힘든 방향으로 학습을 합니다.
(d) 이 과정의 반복의 결과로 real과 fake의 분포가 거의 비슷해져 구분할 수 없을 만큼 G가 학습을 하게 되고 결국, D가 이 둘을 구분할 수 없게 되어 확률을 1/2로 계산하게 됩니다.
'Study > AI' 카테고리의 다른 글
| [AI] ReLU vs Leaky ReLU (0) | 2025.02.07 |
|---|---|
| [AI] 배치 정규화(Batch Normalization)란? (0) | 2025.02.07 |
| [AI] TensorFlow에서 Gradient Tape를 이용한 자동 미분 (0) | 2025.02.06 |
| [AI] TensorFlow 기초 개념과 활용 (0) | 2025.02.06 |



