배치 정규화(Batch Normalization)는 딥러닝 모델의 학습 속도와 안정성을 획기적으로 개선해주는 대표적인 기법 중 하나입니다.
이번 포스팅에서는 Batch Normalization이 무엇이고, 왜 사용하는지에 대해 알아보겠습니다.
Batch란?
Batch Normalization에 대해 알아보기 전에 먼저 Batch가 뭔지 알아야합니다.

Batch란 전체 데이터셋에서 한 번에 모델에 입력으로 제공하는 데이터 샘플들의 묶음을 의미합니다.
왜 이렇게 하냐구요?

전통적인 gradient descent 방법을 사용하면, 학습 데이터 전부를 넣어서 gradient를 다 구하고 그 모든 gradient를 평균해서 한번에 모델 업데이트를 합니다.
그런데 이런 식으로 하면 대용량의 데이터를 한번에 처리하기 어렵습니다. 컴퓨터 메모리에 큰 부담이 가겠죠.
그래서 나온 것이 바로 Batch!
데이터를 작은 묶음으로 나눠 순차적으로 학습하면 이러한 문제를 해결할 수 있습니다.

stochastic gradient descent 방법을 살펴보면, 기존의 전통적인 gradient descent 방법과 달리 gradient를 한번 업데이트 하기 위하여 일부의 데이터(batch size만큼의 데이터)만을 사용하는 것을 알 수 있습니다.
Internal Covariant Shift
그런데 이 batch 방식에는 Internal Covariant Shift라는 치명적인 문제가 있었습니다.
Internal Covariant Shift란 학습 과정에서 계층 별로 입력의 데이터 분포가 달라지는 현상을 말합니다.

쉽게 설명해보겠습니다.
각 계층에서 입력으로 feature를 받으면 그 feature는 convolution이나 위와 같이 fully connected 연산을 거친 뒤 activation function을 적용하게 됩니다.
이렇게 여러가지 연산이 적용되면 연산 전/후에 데이터 간 분포가 달라질 수가 있습니다.
Batch 단위로 이러한 학습이 수행되면 당연하게도 Batch 간에 데이터 분포 차이가 발생할 수 있겠죠.
이렇게 Batch 간에 데이터 차이가 발생하게 되는 문제를 Internal Covariant Shift라고 합니다.
Batch Normalization
그래서 위에서 말한 Internal Covariant Shift 문제를 해결하기 위해 도입된 것이 바로 Batch Normalization입니다.
Batch Normalization은 학습 과정에서 각 배치 단위 별로 데이터가 다양한 분포를 가지더라도 각 배치별로 평균과 분산을 이용해 정규화하는 것을 의미합니다.

위 그림을 보면 batch 간 분포가 다르고, layer 간에도 분포가 다 다른 것을 확인할 수 있습니다.
하지만 이렇게 달랐던 분포를 정규화를 통해 평균이 0, 분산이 1인 가우시안 분포 형태로 만들어주고 있습니다.
이렇게 하면 각 배치 별로 상이했던 데이터 분포를 어느정도 일치시켜줄 수 있게 됩니다.
Batch Normalization은 왜 하는가?
1️⃣ Layer가 깊어짐에 따라 나타나는 분포 변화를 줄여 학습을 안정시킵니다.
Training 셋과 Test 셋의 분포가 다르면 학습이 안된다는 것은 대부분 알고 계실 것입니다.
이와 같은 원리로 신경망에서는 각 layer에 전달되는 feature의 분포가 달라지게 되면 학습하는데 어려움이 생깁니다.
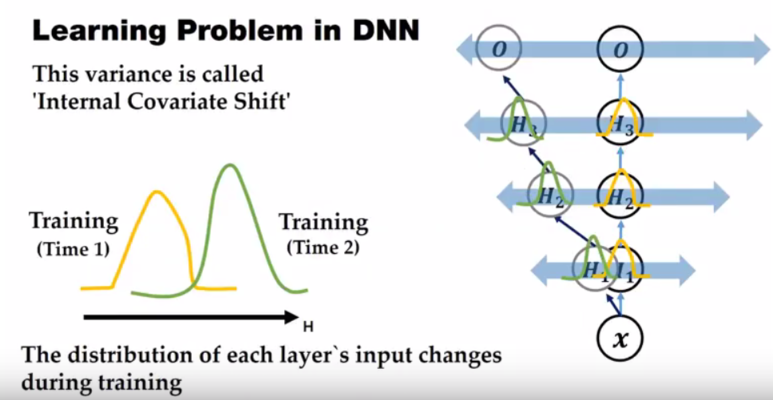
이 문제는 위 그림과 같이 hidden layer의 깊이가 깊어질수록 변화가 누적되어 feature의 분포 변화가 더 커지게 됩니다.
Batch Normalization을 적용하면, 이 문제를 해결할 수 있습니다.

Hidden layer가 깊어짐에 따른 데이터 분포의 변화량이 크지 않게 되면 더욱 안정적인 학습이 가능할 것입니다.
2️⃣ Activation function이 보다 효과적으로 작동할 수 있도록 도와줍니다.
Batch normalization을 진행하면 평균이 0, 분산이 1인 표준 정규 분포를 따르게 됩니다.
그런데 왜 이게 활성화 함수의 효과적인 작동에 도움을 줄까요?
먼저 대표적인 활성화 함수인 ReLU를 살펴봅시다.
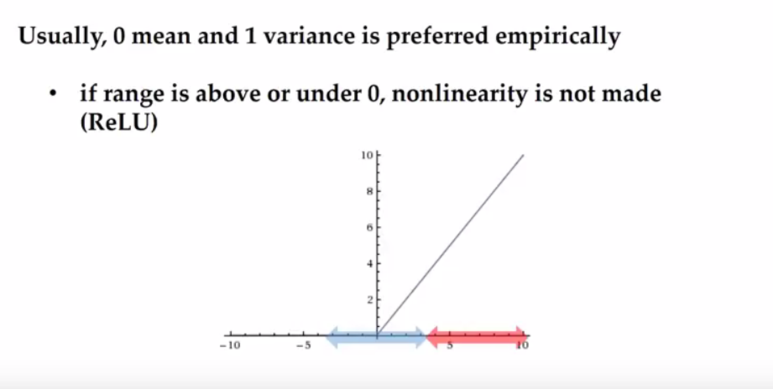
- 빨간색 화살표 : 배치 정규화를 수행하지 않았을 때의 분포
- 모든 데이터가 0보다 커지게 되어 ReLU 함수를 통과하더라도 Non linearity를 줄 수 없게 됨
- 파란색 화살표 : 배치 정규화를 수행했을 때의 분포
- 평균이 0이 되어 음수는 0으로, 양수는 linear 하게 전달되도록 하는 ReLU의 철학이 잘 반영 됨
이러한 해석은 sigmoid 함수에도 적용될 수 있습니다.
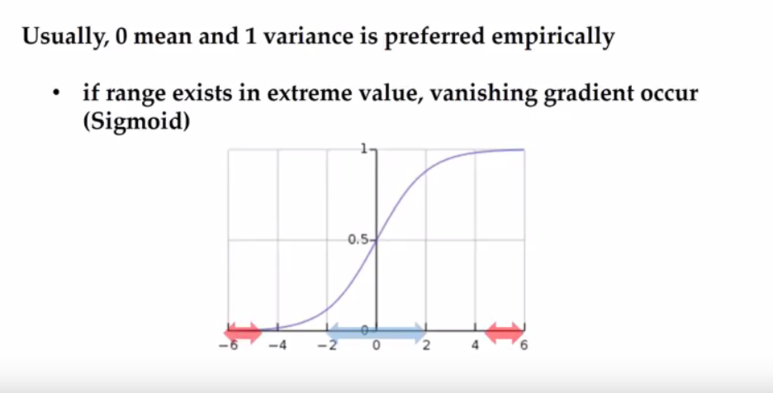
- 빨간색 화살표 : 배치 정규화를 수행하지 않았을 때의 분포
- 데이터가 매우 큰 양수나 매우 작은 음수가 되어 1 또는 0으로 수렴해 버리기 때문에 sigmoid의 의미가 없어짐
(+ vanishing gradient 문제)
- 데이터가 매우 큰 양수나 매우 작은 음수가 되어 1 또는 0으로 수렴해 버리기 때문에 sigmoid의 의미가 없어짐
- 파란색 화살표 : 배치 정규화를 수행했을 때의 분포
- 평균이 0, 분산이 1이 되어 sigmoid 함수를 통과했을 때 유의미한 값이 나오게 됨
Reference
이 포스팅은 아래 JINSOL KIM님의 블로그 내용을 전적으로 참고하였으며, 초심자를 위해 복잡한 수식은 빼고 직관만 가져와서 쉽게 풀어내었습니다.
https://gaussian37.github.io/dl-concept-batchnorm/#batch-1
배치 정규화(Batch Normalization)
gaussian37's blog
gaussian37.github.io
'Study > AI' 카테고리의 다른 글
| [AI] 딥러닝 개발을 위한 CPU, GPU, 메모리 이해하기 (3) | 2025.02.07 |
|---|---|
| [AI] ReLU vs Leaky ReLU (0) | 2025.02.07 |
| [AI] GAN(Generative Adversarial Networks)에 대하여 (1) | 2025.02.06 |
| [AI] CNN(Convolutional Neural Networks)에 대하여 (0) | 2025.01.27 |


