프로젝트 도중 GAN 모델을 써야할 일이 생겼는데, TensorFlow의 공식 문서를 보니 discriminator의 hidden layer에서 ReLU가 아닌 Leaky ReLU를 사용하고 있었습니다.
Leaky ReLU는 무엇이고, 왜 GAN에서 ReLU 대신 쓰는건지 궁금해서 공부한 내용을 포스팅해보려 합니다.
ReLU (Rectified Linear Unit)
✅ 정의
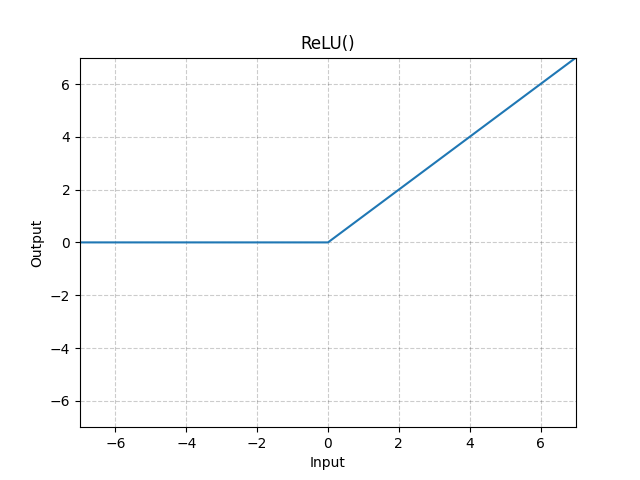
ReLU는 입력 값이 0보다 크면 그대로 출력하고, 0 이하면 0으로 변환하는 활성화 함수입니다.

✅ 특징
- 입력이 0보다 크면 그대로 출력합니다.
- 0 이하의 입력에 대해서는 0을 출력합니다.
- 매우 간단한 연산이므로 계산이 빠르고, 학습 속도가 향상됩니다.
✅ 장점
✔️ Gradient Vanishing 문제 완화:
- Sigmoid나 Tanh 같은 활성화 함수는 역전파 과정에서 기울기(gradient)가 너무 작아져 학습이 느려지는 Gradient Vanishing 문제가 발생할 수 있습니다.
- ReLU는 0 이상의 입력에 대해 기울기가 1이므로 이 문제를 완화할 수 있습니다.
✔️ 계산이 단순:
- max(0,x) 연산만 수행하므로, Sigmoid, Tanh보다 연산량이 적어 빠르게 학습할 수 있습니다.
✅ 단점
❌ Dying ReLU 문제(죽은 ReLU):
- 입력이 0 이하이면 기울기가 0이 되기 때문에, 일부 뉴런이 학습을 하지 못하고 영구적으로 죽어버리는 문제가 발생할 수 있습니다.
- 즉, 특정 뉴런의 가중치가 갱신되지 않아 비활성화 상태로 남을 가능성이 있습니다.
Leaky ReLU (Leaky Rectified Linear Unit)
✅ 정의
Leaky ReLU는 ReLU와 거의 유사하지만, 0 이하의 입력 값에 대해 작은 기울기(α)를 부여하여 죽은 뉴런 문제를 완화한 활성화 함수입니다.
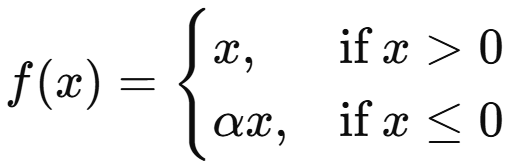
→ 여기서 α는 보통 0.01과 같은 작은 양수입니다.

✅ 특징
- 음수 입력에서도 α만큼 작은 기울기를 남겨두어 기울기가 0이 되는 것을 방지합니다.
- 죽은 뉴런이 생기는 문제를 해결하여 학습이 원활하게 진행됩니다.
✅ 장점
✔️ Dying ReLU 문제 해결:
- 음수 입력에서도 아주 작은 기울기를 유지하기 때문에 뉴런이 죽는 현상을 방지할 수 있습니다.
✅ 단점
❌ 최적의 α 값 선택 필요:
- α 값이 너무 크면 모델이 과소적합(underfitting)될 가능성이 있고, 너무 작으면 Dying ReLU 문제를 충분히 해결하지 못할 수 있습니다.
ReLU vs Leaky ReLU 비교 요약
| ReLU | Leaky ReLU | |
| Dying ReLU 문제 | 존재함 (음수 입력에서 기울기 0) | 해결됨 (α로 음수 입력에서도 학습 가능) |
| 계산 비용 | 낮음 (단순한 연산) | 약간 높음 (α 곱셈 연산 추가) |
| 모델 성능 | 기본적으로 좋음 | 일부 경우 성능 향상 가능 |
| 하이퍼파라미터 조정 | 필요 없음 | α 값 조정 필요 |
언제 ReLU를 사용하고, 언제 Leaky ReLU를 사용해야 할까?
- 대부분의 경우 ReLU가 기본적으로 좋은 선택입니다. 연산이 간단하고 학습 속도가 빠르며, 많은 신경망에서 기본 활성화 함수로 사용됩니다.
- 그러나 만약 ReLU를 사용했을 때 뉴런이 비활성화되어 학습이 잘 안 된다면(Dying ReLU 문제 발생), Leaky ReLU를 고려해볼 수 있습니다.
- 실제로 GAN의 판별자(Discriminator)에서 ReLU 대신 Leaky ReLU를 사용하는 것이 효과적이라는 보고가 있습니다.
- Radford, A. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434.
'Study > AI' 카테고리의 다른 글
| [AI] K-Fold Cross Validation에 대하여 (0) | 2025.03.03 |
|---|---|
| [AI] 딥러닝 개발을 위한 CPU, GPU, 메모리 이해하기 (3) | 2025.02.07 |
| [AI] 배치 정규화(Batch Normalization)란? (0) | 2025.02.07 |
| [AI] GAN(Generative Adversarial Networks)에 대하여 (1) | 2025.02.06 |


