본 포스트에서는 MNIST 손글씨 데이터를 분류하는 모델을 CNN을 통해서 구현해 볼 것입니다.
라이브러리 가져오기
import tensorflow as tf
from tensorflow.keras import datasets
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
import numpy as np
import matplotlib.pyplot as plt
먼저 TensorFlow의 Keras를 사용하여 CNN(Convolutional Neural Network) 모델을 구축하기 위한 필수적인 모듈들을 불러옵니다.
1. from tensorflow.keras import datasets : keras에서 제공하는 다양한 데이터셋을 불러오는 모듈입니다. 여기서는 MNIST 데이터셋을 불러오기 위해 해당 모듈을 import 했습니다.
2. from tensorflow.keras.models import Sequential : 레이어를 쌓아 기본적인 신경망 모델을 구성할 수 있도록 도와주는 모듈입니다. 각 레이어가 이전 레이어의 출력을 입력으로 받는 방식으로 구성됩니다.
3. from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense : CNN 모델을 구축하기 위한 필수적인 레이어들을 불러오는 모듈입니다.
- Conv2D : 2차원 컨볼루션 레이어로, 이미지의 특징을 추출하기 위해 사용됩니다.
- MaxPooling2D : Max Pooling 연산을 수행하는 레이어로, 풀링을 통해 특징 맵의 크기를 줄이고 계산량을 감소시킵니다.
- Flatten : 다차원 특징 맵을 1차원으로 평탄화하는 레이어로, 컨볼루션 레이어와 완전 연결(fully connected) 레이어 사이에 삽입됩니다.
- Dense : 완전 연결 레이어로, 각 뉴런이 이전 레이어의 모든 입력과 연결되어 있는 레이어입니다.
MNIST 데이터 불러오기
# MNIST data
(x_train, y_train), (x_test, y_test) = datasets.mnist.load_data()
print(x_train.shape, y_train.shape, y_train[0])
print(x_test.shape, y_test.shape, y_test[0])
datasets 모듈에 있는 mnist 데이터는 (x_train, y_train), (x_test, y_test) 형태로 구성되어 있기 때문에 형태를 맞추어 변수에 받아줍니다.train set과 test set의 shape은 다음과 같습니다.

- x_train : 28*28 크기 사진이 60000개 들어가있는 변수
- y_train : 각 사진들에 대한 타깃 값
- x_test : 28*28 크기 사진이 10000개 들어가있는 변수
- y_test : 각 사진들에 대한 타깃 값
어떻게 생겼는지 한번 확인해볼까요? 위 코드 결과를 보니 x_train의 0번째 인덱스 값이 5네요. 확인해보겠습니다.
# Train data 확인
img = x_train[0]
print("image.shape =", img.shape)
plt.imshow(img, cmap=plt.cm.binary) # plt.imshow(img,cmap='gray')
plt.show()
흑백 이미지이기 때문에 cmap 옵션은 plt.cm.binary 혹은 'gray'를 사용해줍니다.

코드 실행 결과 숫자 5처럼 생긴 손글씨가 잘 출력된 것을 볼 수 있습니다.
3D tensor 형태로 만들기
# 3D tensor
x_train = x_train.reshape((60000, 28, 28, 1))
x_test = x_test.reshape((10000, 28, 28, 1))
MNIST 데이터는 이미지 데이터이기 때문에 딥러닝을 하기 전에 올바른 shape을 맞춰주는 것이 중요합니다.
근데 뭔가 이상하지 않나요? (60000, 28, 28, 1)이면 4차원인데 왜 3D tensor라고 했을까요?
이미지 데이터는 기본적으로 (samples, height, width, channels) 와 같은 형태를 갖고 있습니다.
여기서 channel이란 쉽게 말하자면 색깔을 담당하는 차원을 의미합니다. 현재 사용하는 MNIST 데이터는 흑백으로 명암의 차이만 존재하기 때문에 채널의 차원은 1이 됩니다. (만약 컬러였다면 3이 되겠죠?)
마지막 차원이 1이라는 것은 어찌보면 4D가 아니라 3D라고 봐도 무방합니다. 그래서 저는 이 형태를 직관적으로 표현하기 위해 4D tensor가 아닌 3D tensor라고 명명하였습니다.
Normalization
# Convert to float32
x_train, x_test = np.array(x_train, np.float32), np.array(x_test, np.float32)
# Normalize images value from [0, 255] to [0, 1]
x_train, x_test = x_train / 255., x_test / 255.
모델이 더 빠르고 안정적으로 수렴하기 위해서는 정규화가 필요합니다. MNIST 데이터셋은 각 픽셀의 값이 0부터 255까지의 정수로 표현되는데, 이를 255로 나누어 줌으로써 0과 1사이의 값으로 변환시켜 줍니다.
CNN 모델 구축하기
CNN 모델 구축에는 크게 2가지 스텝이 있습니다.
1. Feature learning
: 좋은 커널을 찾기 위해 학습하는 과정으로, 2가지 종류의 레이어가 사용됩니다.
- Convolution layer : 여러개의 필터를 적용하여 정보를 압축하는 역할
- Pooling layer : 필요없는 정보를 버리는 역할
2. Fully connected layer 생성
: 추출된 특징을 바탕으로 이미지를 분류하는 역할을 합니다.
Step 1. Feature learning
# Step 1. Feature Learning
model = Sequential()
# Output size formula: { (N - F + 2P) / stride } + 1
# Parameter formula: K(F^2 * C + 1)
# filter number: 32, filter_size = 3x3, (default) stride = 1, padding = 'valid' (= no padding)
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
# output shape = {(28-3/1)}+1 = 26 => feature map = 26 x 26 x 32
# pool_size = 2x2, stride = None, padding = 'valid' (=no padding)
model.add(MaxPooling2D((2, 2)))
# output shape = 26/2 = 13 => feature map = 13 x 13 x 32
model.add(Conv2D(64, (3, 3), activation='relu'))
# output shape = {(13-3)/1}+1 = 11 => feature map = 11 x 11 x 64
model.add(MaxPooling2D((2, 2)))
# output shape = 11/2 = 5.5 => 5 => feature map = 5 x 5 x 64
model.add(Conv2D(64, (3, 3), activation='relu'))
# output shape = {(5-3)/1}+1 = 3 x 3 x 64
Feature learning 과정에서는 위 코드와 같이 convolution layer와 pooling layer를 번갈아가면서 층을 쌓았습니다.
convolution layer에서는 필터의 크기, padding, stride를 사용자가 지정함으로써 압축의 정도를 결정합니다.
첫번째 convolution layer를 보면, input 이미지의 크기가 28*28*1입니다. 이 이미지가 압축을 해당 층을 거친 뒤 26*26*32가 됩니다. 어떻게 이렇게 바뀌게 되는 것일까요?
convolution layer에서는 filter라는 것을 사용하여 원래의 이미지를 훑으면서 정보를 압축해 나갑니다. 그 결과 만들어지는 압축된 이미지의 크기는 다음과 같은 공식으로 구할 수 있습니다.

이 공식을 첫번째 layer에 적용해보면, {(28 - 3 + 2*0) / 1} + 1 = 26이 됩니다.
그렇다면 26*26*32에서 32는 뭘까요? 바로 필터의 개수입니다. 해당 이미지에서 뽑은 32가지 특징이라고 볼 수도 있죠.
필터의 개수가 많아진다는 것은 해당 이미지의 특징을 더 구체적으로 여러 관점에서 보겠다는 건데요, 직관적인 이해를 위해 쉬운 비유를 들어보겠습니다.
장님들이 코끼리를 각각 다른 위치에서 만지고 있다고 해봅시다. 이 경우, 이들 각각이 코끼리에 대해 묘사하는 내용이 다를 것입니다. 누군가는 귀를, 누군가는 코를, 누군가는 다리를 만지고 있겠죠. 하지만 이들이 말하는 각기 다른 정보들은 관점만 다를 뿐 모두 사실인 정보들입니다. 그렇다면 만약 코끼리를 만지는 장님의 수가 더 많아지면 어떻게 될까요? 더 다양한 부위를 만지게 되기 때문에 코끼리에 대한 정보가 더 잘게 쪼개져 이전보다 훨씬 구체화될 것입니다.
Filter의 개수를 늘린다는 것은 코끼리를 만지는 장님의 수를 늘린다는 것과 같은 맥락으로 이해할 수 있습니다.
Pooling은 여기서 max pooling을 사용하였습니다. 이 과정은 pooling size를 정해서 그 안에 있는 값 중 가장 큰 값만을 취하는 방식으로 수행됩니다. 이를 통해 영향력이 적은 값을 버림으로써 feature map의 공간적인 크기를 축소하고 계산량을 줄일 수 있습니다.
Step 2. Fully connected layer 생성
# Step 2. Fully Connected Layer
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
Feature learning을 통해 추출된 특징을 바탕으로 이미지를 분류하는 fully connected layer를 생성합니다.
먼저 flatten 작업을 통해 추출된 특징을 1차원 벡터로 만들어줍니다.
다음으로 64개의 노드를 가진 은닉층을 만들고, 마지막으로 10개의 노드를 가진 층을 만들어 줍니다.
이 때 활성화 함수로 softmax 함수를 사용합니다. 이를 통해 각 클래스에 대한 확률을 출력하도록 함으로써 가장 높은 확률을 가진 클래스를 최종적으로 예측할 수 있게 만들어 줍니다.
이렇게 만들어진 CNN 모델의 summary는 다음과 같습니다.
model.summary()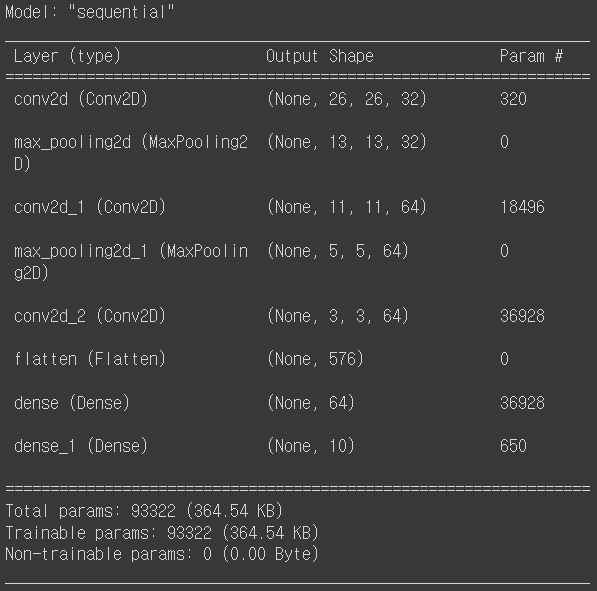
모델 컴파일 : loss function, optimizer, metric 설정
# 모델 컴파일: loss function, optimizer, metric 설정
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy', # label = number
# 'categorical_crossentropy', # label = one-hot
metrics=['accuracy'])
optimizer는 'adam'을 사용하였고, 손실함수는 cross entropy의 일종인 'sparse_categorical_crossentropy'를 사용하였습니다. 평가 metric은 정확도를 사용하였습니다.
모델 학습
# 모델 학습
history = model.fit(x_train, y_train, epochs=5)
시작부터 0.9529로 꽤 높은 정확도를 보입니다. 최종 훈련 성능은 0.9939로 거의 1에 근접하는 성능이 나왔습니다.
loss를 시각화하여 epoch 마다 어떻게 줄어들었는지 직관적으로 확인해보겠습니다.
# Visualize training history
plt.plot(history.history['loss'], label='train')
plt.xlabel('Epochs')
plt.ylabel('Cost')
plt.legend()
plt.show()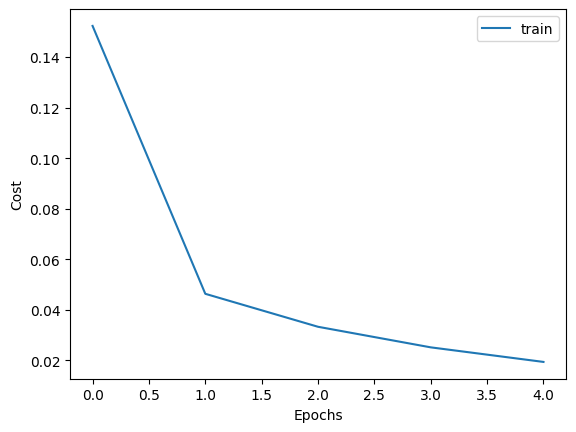
첫 epoch 때 cost가 급격하게 줄어들고, 그 뒤로는 조금씩 줄어들면서 cost가 0에 수렴하고 있음을 확인할 수 있습니다.
훈련은 상당히 잘 되었음이 확인되었으니 이제 test set을 사용하여 모델을 최종적으로 평가해보도록 하겠습니다.
모델 평가
# 모델 평가
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print("테스트 정확도:", test_acc)

테스트 셋에서는 정확도가 0.992가 나왔습니다. train set에서보다 조금 낮은 것으로 보아 오버피팅의 가능성도 무시할 수 없어 보입니다.
predictions = model.predict(x_test)
predictions[0] # 첫번째 예측치
print(np.argmax(predictions[0])) # 예측값
print(y_test[0]) # 실제값
첫번째 예측치는 잘 맞췄군요. 다른 값들도 위와 같은 방식으로 일일이 확인해볼 수 있습니다.
'Study > AI' 카테고리의 다른 글
| [AI] 인공지능 윤리에 관하여 (1) | 2024.08.16 |
|---|---|
| [AI] Artificial Intelligence 인공지능 입문 강의 (POSTECH 유환조 교수님) (0) | 2024.06.07 |
| [AI] 혼동 행렬(Confusion matrix) 직접 구현하기 (0) | 2024.03.26 |
| [AI] 로지스틱 회귀(Logistic Regression) 직접 구현하기 (0) | 2024.03.25 |


