본 포스트에서는 Tensorflow에서 로지스틱 회귀를 구현해볼 것입니다.
먼저 필요한 라이브러리들을 가져옵니다.
라이브러리 가져오기
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
훈련 데이터 생성
x_train = np.array([[1., 1.],
[1., 2.],
[2., 1.],
[3., 2.],
[3., 3.],
[2., 3.]],
dtype=np.float32)
y_train = np.array([[0.],
[0.],
[0.],
[1.],
[1.],
[1.]],
dtype=np.float32)
X는 2차원 상의 데이터 포인트이고, Y는 0 또는 1로만 이루어져 있는 결과 값입니다.
훈련 데이터들을 시각화 해보면 다음과 같습니다.
colors=['red' if i==0 else 'blue' for i in y_train]
plt.scatter(x_train[:, 0], x_train[:, 1], label='Logistics regression', color=colors)
plt.show()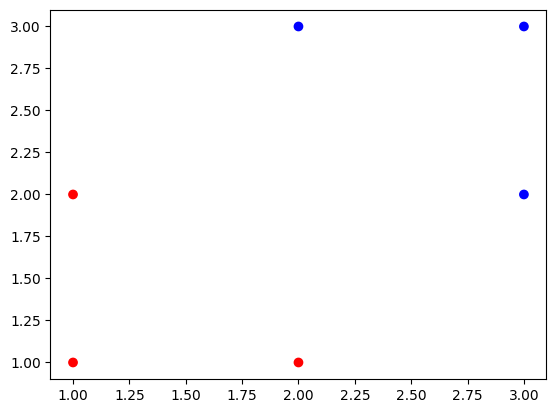
이제 빨간색 점들과 파란색 점들을 가장 잘 분류하는 선을 찾아야 합니다.
가설 정의
# Hypothesis and Prediction Function
tf.random.set_seed(42) # 시드 고정
W = tf.Variable(tf.random.normal([2, 1], mean=0.)) # 정규분포에서 랜덤으로 값을 생성하여 크기가 [2, 1]인 배열 생성
b = tf.Variable(tf.random.normal([1], mean=0.))
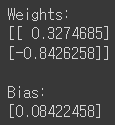
print(' Weights: \n', W.numpy(), '\n\n Bias: \n', b.numpy())
def hypothesis(X):
z = tf.matmul(X, W) + b # Wx + b 식 만들기 (matmul은 행렬곱 함수)
sigmoid = 1 / (1 + tf.exp(-z)) # sigmoid 함수에 만든 식 넣기
return sigmoid
먼저 시드를 고정해준 뒤, 기울기와 편향을 랜덤으로 생성해줍니다.
W는 왜 [2, 1] 크기 배열이냐구요? 위에서 보셨다시피 X가 2차원 상의 데이터 포인트 좌표여서 이 크기에 맞춰준 것입니다.
생성된 초기 값을 출력해보면 오른쪽과 같이 나옵니다.
hypothesis를 볼까요? 단순 선형회귀의 hypothesis와 차이점이 하나 보입니다.
로지스틱 회귀에서는 Wx + b가 sigmoid라는 함수를 통과하고 있음을 확인할 수 있습니다. 왜 이런걸 사용하는 걸까요?
이 문제는 이진 분류 문제이기 때문에 결과 값이 0 또는 1로만 나와야하는데, Wx + b만 계산하면 연속적인 값이 나오게 됩니다.그러면 안되겠죠? 0 또는 1로 결과를 판단하려면 해당 입력값이 0에 가까운지, 1에 가까운지를 알아야 합니다. sigmoid 함수가 바로 이것을 도와주는 역할을 합니다. 결과값이 1일 확률을 도출시켜주는 역할을 하는 것이죠.즉, sigmoid 함수에 특정 값을 넣으면 0부터 1까지의 값이 나오게 되는데, 이 값이 바로 결과값이 1일 확률이 되는 것입니다.
이 확률을 알면 뭐하냐구요? 나중에 따로 기준점을 설정해서 해당 확률이 기준점보다 높으면 1, 낮으면 0으로 판단할 수 있게 됩니다.
손실 함수(cost function) 정의
def cost_fn(H, Y): # H: 예측값, Y: 실제값
# 로지스틱에서는 손실함수로 Cross-Entropy Loss 함수 사용이 일반적
cost = -tf.reduce_mean(Y*tf.math.log(H) + (1-Y)*tf.math.log(1-H))
return cost
cost function 역시 로지스틱 회귀에서는 좀 다릅니다. 단순 선형회귀에서는 MSE를 사용했었는데, 여기서는 Cross-Entropy라는 함수를 사용하게 됩니다.
Cross-Entropy Loss의 식은 다음과 같습니다.
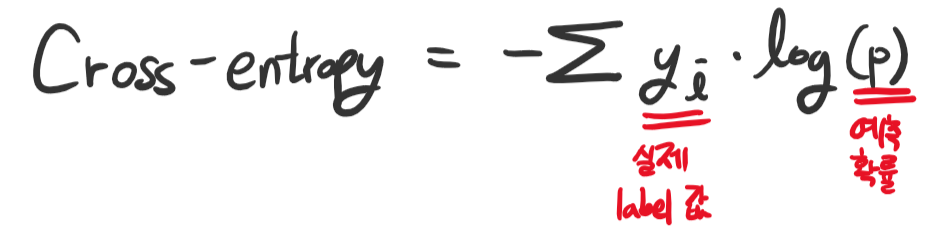
그런데 코드에 적혀있는 식과 좀 다르죠? 맞습니다. 위 식은 일반화된 Cross-entropy 함수이고, 저는 지금 binary classification, 즉 이진 분류를 하고 있기 때문에 특수한 케이스에 속합니다.
이진 분류의 경우 Binary Cross-entropy 함수를 사용하게 됩니다.
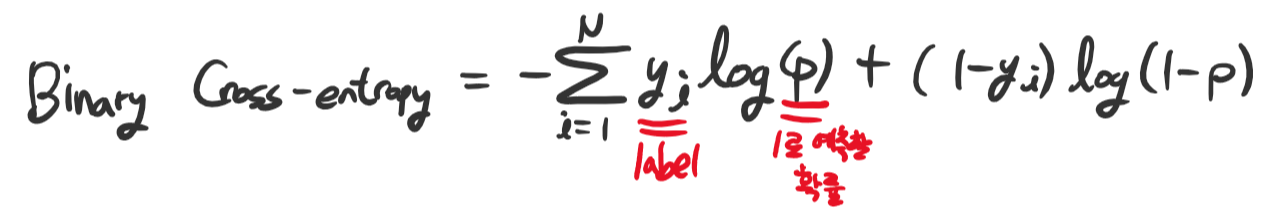
최적화 알고리즘 (optimizer) 선택
optimizer = tf.optimizers.SGD(learning_rate=0.01)
cost function을 최소화하기 위해 optimizer를 정합니다.
여기서는 Stochastic Gradient Descent (SGD) 알고리즘을 사용했습니다.
모델 학습
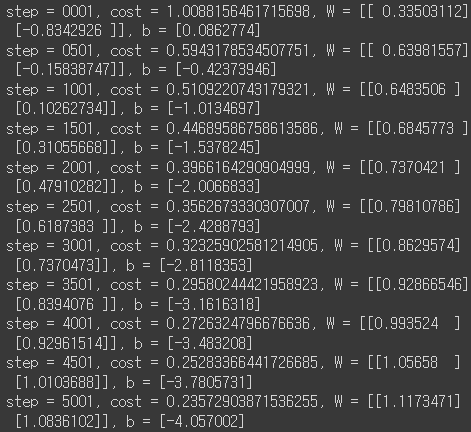
for step in range(5001):
# tf.GradientTape를 사용하여 모델을 훈련. 자동 미분을 위한 tf.GradientTape 함수 사용
with tf.GradientTape() as g:
pred = hypothesis(x_train)
cost = cost_fn(pred, y_train)
# gradient 계산
gradients = g.gradient(cost, [W, b])
# gradients에 따라 W와 b 업데이트
optimizer.apply_gradients(zip(gradients, [W, b]))
# display
if step % 500 == 0:
print(f'step = {step+1:0>4}, cost = {cost}, W = {W.numpy()}, b = {b.numpy()}')
w_hat = W.numpy()
b_hat = b.numpy()
tf.GradientTape()를 이용해서 gradient를 계산하고, gradient를 따라 W, b를 업데이트하는 과정을 5001번 반복합니다.
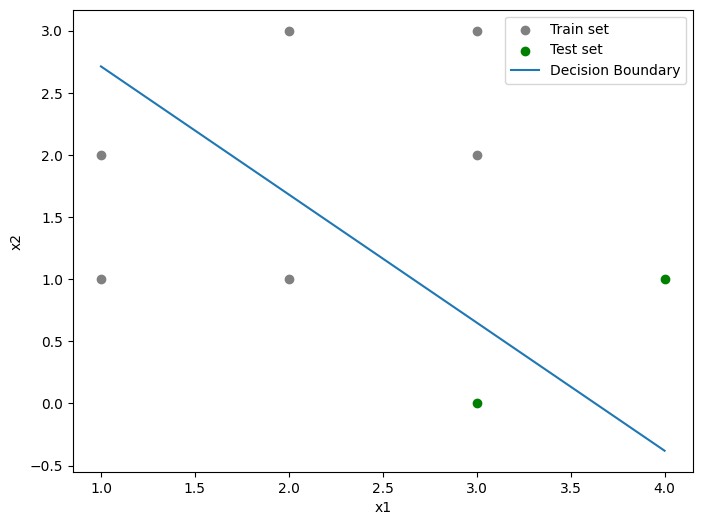
시각화
# Plotting the decision boundary: w1*x1 + w2*x2 + b = 0
# y_hat = x2 = - w1/w2 * x1 - b/w2
slope = w_hat[0]/w_hat[1]
xx = np.linspace(np.min(x_train[:, 0]), np.max(x_train[:, 0])) # x_train의 x값 범위만큼 값을 연속적으로 생성
yy = - slope*xx - b_hat/w_hat[1] # 생성된 분류선 식 (연속적 x에 대한 y값)
colors=['red' if i==0 else 'blue' for i in y_train]
plt.xlabel('x1')
plt.ylabel('x2')
plt.scatter(x_train[:, 0], x_train[:, 1], label='Logistics regression', color=colors) # x_train 포인트 생성
plt.plot(xx, yy, label='Decision Boundary') # 분류선 생성
plt.show()
decision boundary의 식은 w1*x1 + w2*x2 + b = 0 형태입니다.이것을 x2에 대해서 나타내면 x2 = - w1/w2 * x1 - b/w2 형태가 됩니다.위 내용을 바탕으로 분류선을 시각화하면 아래와 같이 나타나게 됩니다.
예측
# Test data
x_test = np.array([[3., 0.],
[4., 1.]],
dtype=np.float32)
y_test = np.array([[0.],
[1.]],
dtype=np.float32)
# Accuracy
def accuracy(hypo, label):
# 모델의 예측값 'hypo'가 0.5보다 크면 1로, 아니면 0으로 변환하여 이진 분류 결과 생성
# tf.cast로 불리언 값을 tf.float32 형식으로 변환
pred = tf.cast(hypo > 0.5, dtype=tf.float32)
# tf.equal로 pred와 label이 일치하면 True, 불일치하면 False 반환
# tf.cast로 불리언 값을 tf.float32 형식으로 변환
# tf.reduce_mean으로 accuracy 구함
acc_ = tf.reduce_mean(tf.cast(tf.equal(pred, label), dtype=tf.float32))
return acc_
acc = accuracy(hypothesis(x_test), y_test).numpy()
print(f'Accuracy:{acc}\n')
# Prediction
x_test_predict = hypothesis(x_test)
print("Prob: \n", x_test_predict.numpy()) # sigmoid를 통과한 결과 확률값
print("Result: \n", tf.cast(x_test_predict > 0.5, dtype=tf.float32).numpy()) # 확률값에 대해 threshold 적용한 최종 예측 label
테스트 데이터를 이용해 모델이 데이터를 올바르게 분류하는지 확인해보았습니다. 테스트 데이터는 아래와 같이 0, 1 각각 하나씩 만들었습니다.
간단한 모델이므로 accuracy 지표만 확인해보았습니다. 기준점을 0.5로 하여 0.5보다 작으면 0, 크면 1로 분류되도록 하였습니다.
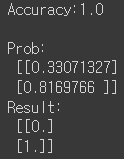
Accuracy는 1.0으로, 두 개의 테스트 데이터를 모두 맞췄습니다.
'Study > ML' 카테고리의 다른 글
| [ML] 혼동 행렬(Confusion matrix) 직접 구현하기 (0) | 2024.03.26 |
|---|---|
| [ML] 선형 회귀(Linear Regression) 직접 구현하기 (2) | 2024.03.25 |

