인공지능 문제의 특징

1. Computational Complexity : 최적의 솔루션을 찾는데 너무 오랜 시간이 걸린다.
2. Information Complexity : 최적의 솔루션을 찾는데 너무 많은 양의 데이터가 필요하다.
인공지능 문제 해결을 위해 필요한 자원 (Challenges)
=> 즉, 인공지능 문제를 풀기 위해서는 다음 두 가지가 필요하다.

인공지능 문제 해결 접근 시 고려해야 할 것들
=> 좀 더 구체적으로, 인공지능 문제 해결에 접근하기 위해서는 다음 세 가지를 고려해야 한다.

인공지능 문제 접근법
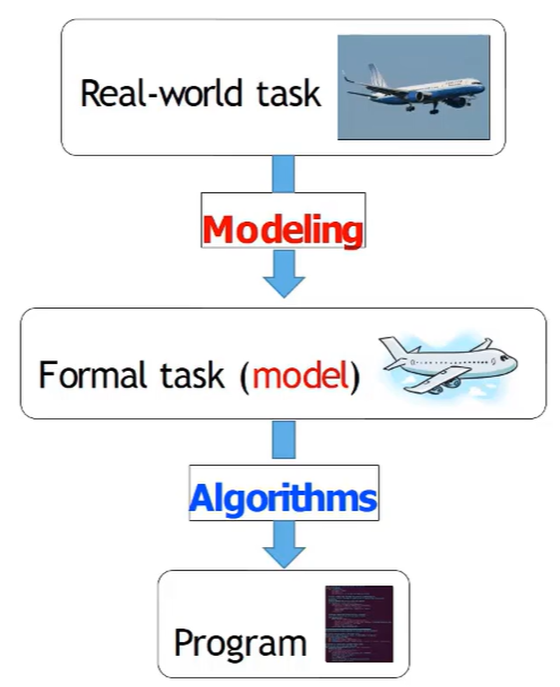
인공지능 문제에 대한 접근은 real world task에 대해 모델링을 적용하여 formal task로 바꾸고, 알고리즘을 적용하여 프로그램을 만드는 형태로 이루어진다.
모델링과 알고리즘

- 인공지능 문제에 접근할 때에는 무엇을 계산할 것인지(모델링)와 어떻게 계산할 것인지(알고리즘)를 구분하여 접근한다.
- 우리는 이를 위해 무엇을 배워야 하는가?
- 모델의 종류
- 모델을 어떻게 구성하고, 어떻게 학습을 시키는지
- 모델을 빠르게 푸는 알고리즘을 개발하는 법
Reflex-based Model

=> 가장 단순한 인공지능 모델

x가 들어오면 단순히 f(x)를 통과시킨 함수값을 내놓는 방식
ex) linear classifier
State-based Model
중국어는 띄어쓰기 없음. 아라비아 언어는 모음이 없음. 영어에서 모음, 띄어쓰기 빼면 이상한 단어가 됨.
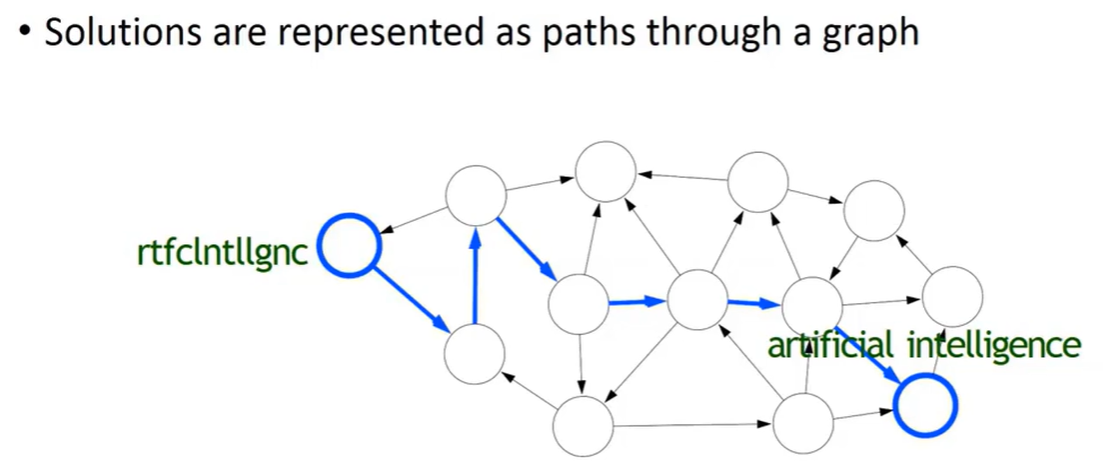
영어에서 모음, 띄어쓰기를 빼보자.
rtfcIntllgnc
위와 같은 이상한 단어가 되었다. 이건 원래 무슨 단어였을까?
바로 Artificial Intelligence에서 모음과 띄어쓰기가 제거된 모습이다.
그럼 우리는 어떻게 저 글자만 보고 Aritificial Intelligence라고 유추해낼 수 있었을까?
위 그림에서 각각의 동그라미 하나를 state라고 한다.

다시 말해, 미래에 최적으로 행동하기 위해 과거에 대한 모든 관련 정보를 포착하는 어떠한 것을 state라고 한다.
우리는 어릴 때부터 영어 단어를 많이 접해왔기 때문에 위와 같은 state가 형성이 되어 있고, path를 따라 서칭하며 결국 Aritificial Intelligence라는 정답을 찾아낸 것이다.
인공지능도 마찬가지다. 인공지능에게 책을 많이 읽히면, 언어 모델을 스스로 학습하게 된다. 그런 다음 state-based 알고리즘을 돌리게 되면 컴퓨터가 최적의 경로를 찾아내게끔 만들 수 있다.
Variable-based Model
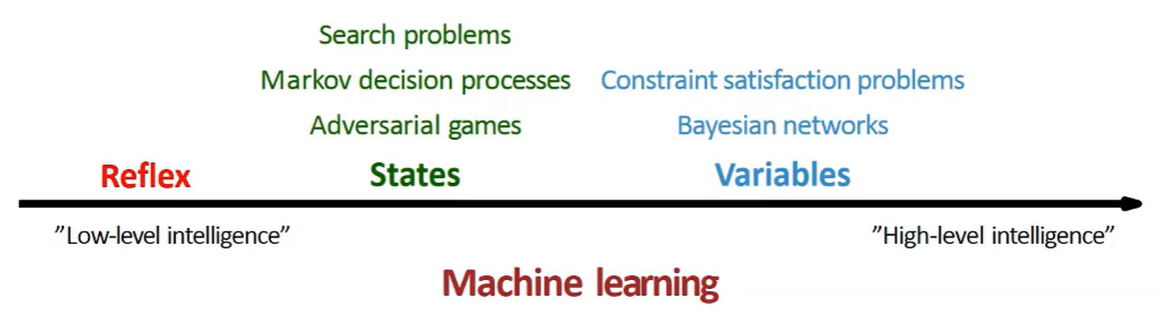
*state-based model과 variable-based model의 차이
- state-based model : 어떤 목적을 달성하기 위해 최적의 sequence of action을 찾음
- variable-based model : 각각 variable들에 value가 들어갈 수 있는데, 가장 바람직한 value assignment를 찾음
Prediction tasks


위와 같이 여러 종류의 prediction task가 존재한다.
그러나 결국 이 모든 것은 아래 framework를 따른다.
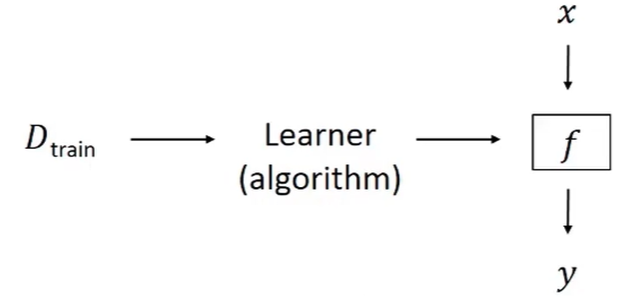
학습 데이터가 들어오면, 알고리즘이 이를 학습하고, 모델 f를 찾아준다. 그리고 새로운 데이터 x가 왔을 때, y를 자동으로 예측해낸다는게 전반적인 framework이다.
그런데 생각해보면 함수 f를 모델링한다는건, 최적의 파라미터를 찾아낸다는 것이고,
이는 결국 optimization 문제로 귀결된다.
모델링 문제는 최적의 w를 찾는 것인데, 최적의 w를 찾기 위해서는 loss function을 최소화시키는 w를 찾는 방식, 즉 optimization 문제를 해결해야 하는 것이다.
다시 말해, Modeling = Optimization 이라고 볼 수 있다!!
Generalization

Q. 위 두 모델 중 어떤 모델이 외부 데이터 셋에 대해 성능이 더 좋을까?
오른쪽이 학습 데이터를 완벽하게 학습했으니 더 좋을 것이라고 생각하는가?
정답은 왼쪽 모델이다. 오른쪽 모델은 학습 데이터에 너무 fit해져서 일반성이 떨어진다. 이러한 경우를 오버피팅이라고 한다.
Generalization이란 이러한 오버피팅을 피해 새로운 데이터가 들어와도 여전히 좋은 성능을 유지할 수 있도록 하는 작업을 의미한다.
오버피팅을 피하는 방법
1. Feature selection : 피쳐를 줄인다. (차원을 줄여 모델의 복잡도를 낮춤)
2. Hyperparameters : 에러를 최소화하는 방향으로 하이퍼파라미터 튜닝을 한다. (validation set 사용)
'Study > Lecture' 카테고리의 다른 글
| [Python] 클래스(class) (0) | 2024.06.27 |
|---|
