이번 포스팅에서는 딥러닝(Deep Learning)의 핵심적인 구조 중 하나인 CNN(Convolutional Neural Networks), 즉 합성곱 신경망에 대해 알아보겠습니다.
CNN은 이미지 처리와 관련된 작업에서 상당한 성능을 보여주며, 딥러닝 모델 중에서도 매우 널리 사용되고 있습니다.
이 글에서는 CNN의 기본 개념부터, 주요 구성 요소, 작동 원리에 대해 자세히 알아보겠습니다!
CNN이란?
CNN(Convolutional Neural Nets)은 이미지 및 영상 등의 특징을 식별(detection)하고 분류(classification)하는데 널리 사용되는 딥러닝 기본 모델입니다.
CNN의 구성

CNN은 크게 2가지 단계로 구성됩니다.
1. Feature learning : 공간정보를 유지하면서 image의 특징을 추출
- Convolution Layer: 필터를 적용해 이미지에서 중요한 특징(선, 모양 등)을 찾아냄
- ReLU: 활성화 함수로, 음수를 0으로 바꾸어 비선형성을 추가
- Pooling Layer: 이미지 크기를 줄이면서 중요한 정보만 남김 (예: Max Pooling, Average Pooling ..)
2. Classification : class를 분류
- Flatten Layer: 추출된 특징을 1차원 배열로 변환
- Fully Connected Layer: 추출된 특징을 활용해 클래스별 점수(logits)를 계산
- Softmax Layer: 점수를 확률로 변환해 최종적으로 예측 클래스 결정
위 그림에서는 Feature learning 이후의 단계를 Classification이라고 가정했지만,
실제로는 목적에 따라 달라질 수 있습니다!
Feature Learning의 흐름
Feature learning 부분은 아래 4가지 단계로 설명할 수 있습니다.

이제 위 4가지 단계를 하나하나 살펴봅시다.
훑어보기 - Convolution Layer
CNN 모델은 어떻게 이미지를 훑어볼까요?
그 원리에 대해 이해해봅시다!
Convolution Layer는 필터(커널)을 이용하여 이미지에서 특정 특징을 뽑아내는 역할을 하는 층입니다.
어떤 원리로 특징을 뽑아내는지 한번 살펴보겠습니다!

이미지에 필터를 곱해서 특징을 추출해내는 것이 끝입니다. 간단하죠?
곱하는 건 어떻게 곱하느냐?
바로 이렇게 계산됩니다.

파란색 부분만 계산해볼까요?

같은 위치 칸끼리 곱하고 각 칸에서 나온 값들을 합하면 이렇게 19가 나오게 됩니다.
나머지 부분도 같은 방식으로 이렇게 계산이 되겠죠!
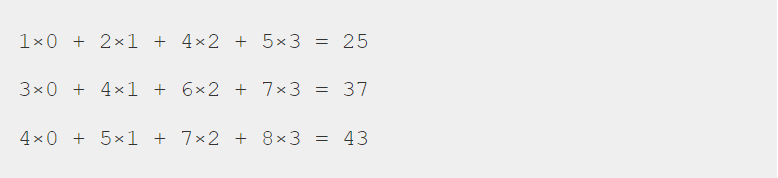
정렬하기 - Batch Normalization
다 훑어봤으면, 이제 필터에 맞게 보고 싶은 특징 정보만 남게 됩니다.
그러면 데이터가 변형이 되는데요, 이것을 다시 정렬(정규화)해주는 작업이 필요합니다.
정렬한다는 것은 값 분포를 정규화해준다는 건데요, 한번 구체적으로 알아보도록 하죠.
Convolution layer를 통과한 후 데이터는 아래와 같이 변형이 될 수 있습니다.
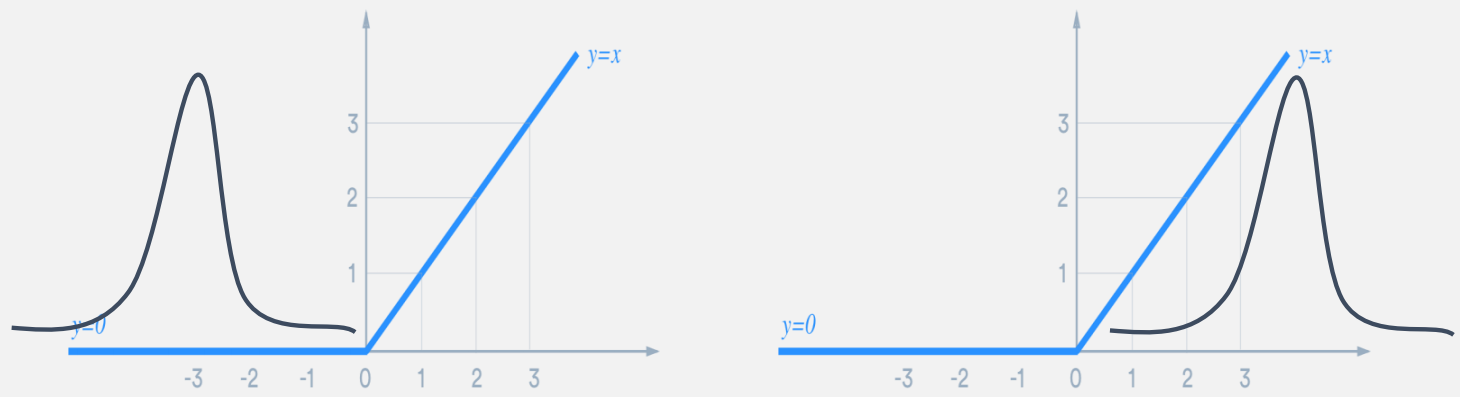
이렇게 데이터 분포가 치우치게 되면, 특정 입력 값에 대해 활성화 함수가 적절히 작동하지 못합니다.
이렇게 치우친 분포를 아래와 같이 정렬해주는 작업을 바로 Batch Normalization이라고 합니다!

Batch normalization을 적용하여 데이터 분포가 평균이 0이고 분산이 1인 형태로 조정이되면, 데이터 분포가 ReLU의 효과적인 영역으로 이동하여 학습이 더 효율적으로 이루어질 수 있게 됩니다.
신호 변환하기 - Activation Function
앞서 batch normalization을 수행했던 이유이기도 하죠.
신호 변환하기의 정체는 바로 "활성화 함수"였습니다!
활성화 함수의 주된 목적은 유의미한 신호는 남기고, 필요없는 신호는 버려 원활한 신호 전달을 돕기 위함입니다.
활성화 함수에는 아래와 같이 여러가지 종류가 있습니다.
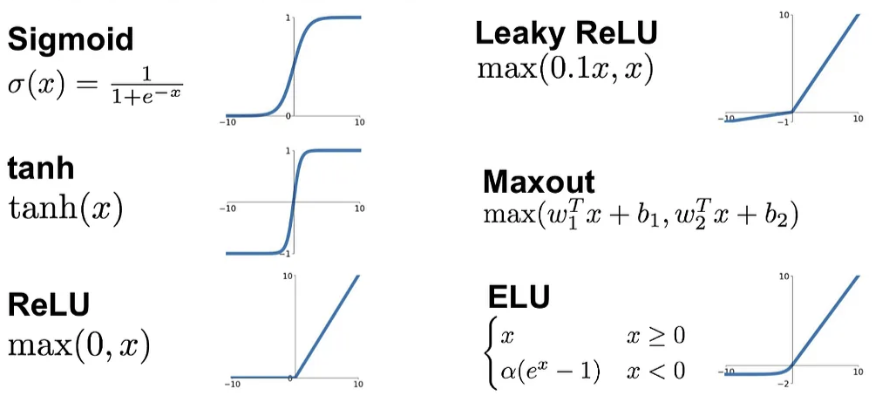
이 중에서도 대부분의 딥러닝 모델에 일반적으로 사용되는 것은 ReLU 함수입니다.
이미지 줄이기 - Pooling
이 정도면 충분히 유의미한 정보만 남겼다고 생각이 드는데, 아직 한번 더 남았습니다.
마지막으로 불필요한 정보를 제거하는 과정인 "Pooling"입니다!
Pooling은 이미지나 데이터의 공간 정보를 줄이는 작업을 말합니다.
Pooling에도 여러가지 종류가 있는데, 그 중에서 대표적으로 사용되는 Max Pooling에 대해 살펴볼까요?

위 그림을 보시면 빨간색, 노란색, 파란색, 초록색 영역이 있습니다.
Max Pooling은 각 영역에서 가장 큰 수만 뽑아내고 다른 수는 버리는 작업입니다.
영역이 4개였으니, 총 4개의 수만 뽑히게 되어 4x4가 2x2로 바뀌게 되죠.
데이터 손실이 클 것 같은데.. 왜 pooling을 할까요?
중요한 특징만 남겨 특징을 강조하고, 차원을 축소하여 계산 효율성을 높이기 위함입니다!
이는 모델의 오버피팅을 방지하는 효과도 낼 수 있죠!
Feature Learning 이후의 작업 방식
Feature learning을 통해 이미지의 특징을 뽑아냈다면, 그 이후는 목적에 따라 모델링 방식이 달라질 수 있습니다.
대표적인 방식 4가지를 살펴보겠습니다.
- Classification (분류)
- Segmentation (분할)
- Detection (탐지)
- Generation (생성)
Classification (분류)
Classification은 "Input이 무엇에 해당하는지 분류하여 Output 출력"하는 작업입니다.

위 예시를 보면 알 수 있듯이, 어떤 엑스레이 사진이 들어오면 이 환자가 폐렴인지 결핵인지 코로나인지 분류해주는,
바로 그런 작업을 classification이라 합니다.
Segmentation (분할)
Segmentation은 "Input의 특정 영역을 추출하여 Output 출력"하는 작업입니다.
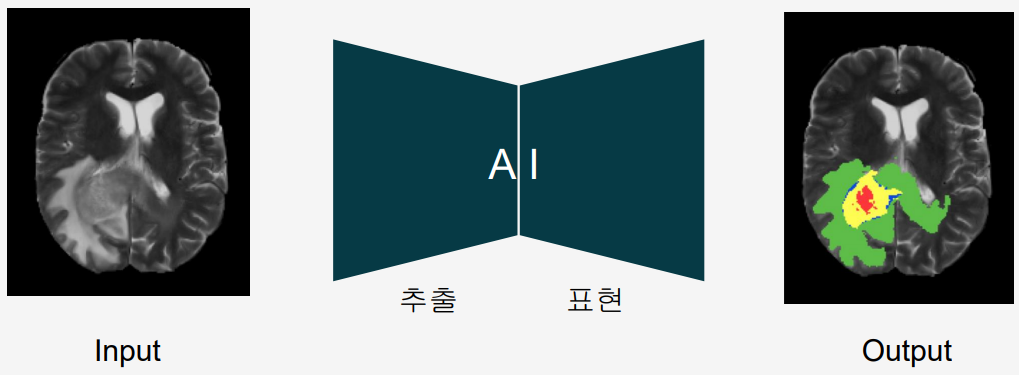
위 예시를 보면, 종양이 있는 부위를 AI가 색칠해서 보여주고 있습니다.
이렇게 특정 부위를 인식하고 추출해주는 작업을 segmentation이라고 합니다.
Detection (탐지)
Detection은 "Input의 특정 영역을 포착하여 Output 출력"하는 작업입니다.

Detection은 특정 부위를 인식한다는 점에서 segmentation과 유사하지만,
다른 점은 "정확한 좌표"를 알려주는다는 것입니다.
Generation (생성)
Generation은 "Input의 특정 영역을 추출하여 Output 출력"하는 작업입니다.

Generation은 말 그대로 Input을 기반으로 새로운 영상을 생성해주는 것을 의미합니다.
위 예시를 보면 노이즈가 많은 영상에 대해 화질이 개선된 새로운 영상을 AI가 생성해준 것을 확인할 수 있습니다.
'Study > AI' 카테고리의 다른 글
| [AI] 배치 정규화(Batch Normalization)란? (0) | 2025.02.07 |
|---|---|
| [AI] GAN(Generative Adversarial Networks)에 대하여 (1) | 2025.02.06 |
| [AI] Model-Centric AI & Data-Centric AI (0) | 2024.12.05 |
| [AI] 인공지능 윤리에 관하여 (1) | 2024.08.16 |


