📌 문제
문제 설명
대장균들은 일정 주기로 분화하며, 분화를 시작한 개체를 부모 개체, 분화가 되어 나온 개체를 자식 개체라고 합니다.
다음은 실험실에서 배양한 대장균들의 정보를 담은 ECOLI_DATA 테이블입니다. ECOLI_DATA 테이블의 구조는 다음과 같으며, ID, PARENT_ID, SIZE_OF_COLONY, DIFFERENTIATION_DATE, GENOTYPE 은 각각 대장균 개체의 ID, 부모 개체의 ID, 개체의 크기, 분화되어 나온 날짜, 개체의 형질을 나타냅니다.
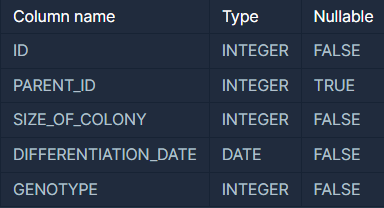
최초의 대장균 개체의 PARENT_ID 는 NULL 값입니다.
문제
대장균 개체의 크기를 내림차순으로 정렬했을 때 상위 0% ~ 25% 를 'CRITICAL', 26% ~ 50% 를 'HIGH', 51% ~ 75% 를 'MEDIUM', 76% ~ 100% 를 'LOW' 라고 분류합니다. 대장균 개체의 ID(ID) 와 분류된 이름(COLONY_NAME)을 출력하는 SQL 문을 작성해주세요. 이때 결과는 개체의 ID 에 대해 오름차순 정렬해주세요 . 단, 총 데이터의 수는 4의 배수이며 같은 사이즈의 대장균 개체가 서로 다른 이름으로 분류되는 경우는 없습니다.
예시
예를 들어 ECOLI_DATA 테이블이 다음과 같다면
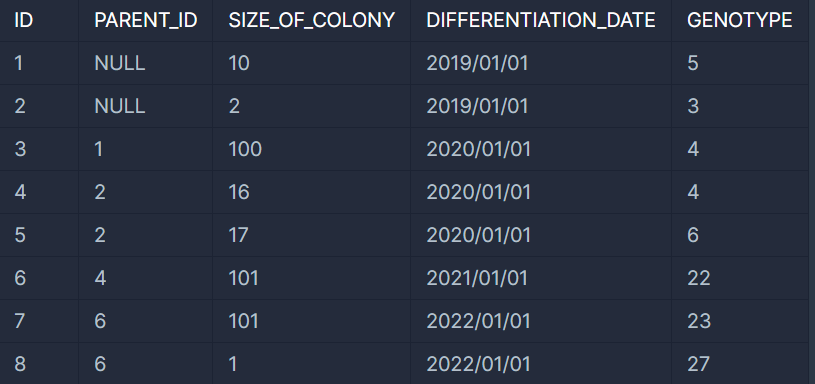
기준에 의해 분류된 대장균들의 ID는 다음과 같습니다.
CRITICAL (상위 0% ~ 25%) : ID 6, ID 7
HIGH (상위 26% ~ 50%) : ID 3, ID 5
MEDIUM (상위 51% ~ 75%) : ID 1, ID 4
LOW (상위 76% ~ 100%) : ID 2, ID 8
따라서 결과를 ID 에 대해 오름차순 정렬하면 다음과 같아야 합니다.

📌 나의 풀이
Code
SELECT ORIGIN.ID,
CASE
WHEN SUB.PERCENT <= 0.25 THEN 'CRITICAL'
WHEN SUB.PERCENT < 0.50 THEN 'HIGH'
WHEN SUB.PERCENT < 0.75 THEN 'MEDIUM'
ELSE 'LOW'
END AS COLONY_NAME
FROM (SELECT ID, PERCENT_RANK() OVER(ORDER BY SIZE_OF_COLONY DESC) AS PERCENT
FROM ECOLI_DATA) AS SUB
INNER JOIN ECOLI_DATA AS ORIGIN
ON ORIGIN.ID = SUB.ID
ORDER BY ORIGIN.ID;
Solution
1. PERCENT_RANK() OVER(~~)을 사용하여 SIZE_OF_COLONY를 기준으로 내림차순(DESC)으로 순위 매기고, 해당 컬럼의 이름을 PERCENT로 명명
- PERCENT_RANK() 함수는 SIZE_OF_COLONY를 백분율로 순위 매김
2. ID와 PERCENT만 가져온 서브쿼리와 원래 테이블을 ID를 기준으로 INNER JOIN
3. CASE ~ END문을 사용하여 PERCENT(백분율 순위) 값에 따라 네 가지 등급으로 나누고, 해당 컬럼의 이름을 COLONY_NAME으로 명명
- PER <= 0.25일 때 'CRITICAL'
- PER <= 0.5일 때 'HIGH'
- PER <= 0.75일 때 'MEDIUM'
- 그 외에는 'LOW'
4. ID 컬럼 기준으로 오름차순 정렬
5. ID 컬럼과 COLONY_NAME 컬럼만 출력
📌 다른 사람의 풀이
Code
SELECT A.ID,
CASE
WHEN A.PER <= 0.25 THEN 'CRITICAL'
WHEN A.PER <= 0.5 THEN 'HIGH'
WHEN A.PER <= 0.75 THEN 'MEDIUM'
ELSE 'LOW'
END AS COLONY_NAME
FROM(
SELECT ID,
PERCENT_RANK() OVER (ORDER BY SIZE_OF_COLONY DESC) AS PER
FROM ECOLI_DATA
) AS A
ORDER BY A.IDSolution
1. PERCENT_RANK() OVER(~~)을 사용하여 SIZE_OF_COLONY를 기준으로 내림차순(DESC)으로 순위 매기고, 해당 컬럼의 이름을 PER로 명명
- PERCENT_RANK() 함수는 SIZE_OF_COLONY를 백분율로 순위 매김
2. ID와 PER만 가져온 서브쿼리에서 이후 작업
3. CASE ~ END문을 사용하여 PERCENT(백분율 순위) 값에 따라 네 가지 등급으로 나누고, 해당 컬럼의 이름을 COLONY_NAME으로 명명
- PER <= 0.25일 때 'CRITICAL'
- PER <= 0.5일 때 'HIGH'
- PER <= 0.75일 때 'MEDIUM'
- 그 외에는 'LOW'
4. ID 컬럼 기준으로 오름차순 정렬
5. ID 컬럼과 COLONY_NAME 컬럼만 출력
배운 내용
1. 습관적으로 JOIN을 사용하지 말자. 사용해야 할 때와 하지 않아야 할 때를 잘 구분해야 한다.
저는 이 문제에서 쓸데없이 INNER JOIN을 사용했는데,
다른 사람의 코드를 보고 다시 생각해보니 굳이 JOIN을 할 필요가 없었다는 것을 깨달았습니다.
중간 중간에 계속 현재 테이블 상태를 출력해보면서 쿼리를 짰다면 이런 실수가 나오지 않았겠죠 ㅠㅠ
조심해야 할 것 같아요!
2. PERCENT_RANK() OVER(~~) 사용법을 잘 기억하자.
이 외에도 비슷한 기능을하는 RANK() OVER(~~)가 있는데,
코딩 테스트에 나올 가능성이 있으니 모두 잘 기억해둬야겠습니다.
모르면 무조건 틀리는 거니까요!
'Coding Test > Programmers' 카테고리의 다른 글
| [Programmers / MySQL] 물고기 종류 별 대어 찾기 (Level 3) (1) | 2024.09.15 |
|---|---|
| [Programmers / MySQL] 특정 세대의 대장균 찾기 (Level 4) (1) | 2024.09.14 |
| [Programmers / MySQL] 대장균의 크기에 따라 분류하기 1 (Level 3) (1) | 2024.09.12 |
| [Programmers / MySQL] 대장균들의 자식의 수 구하기 (Level 3) (0) | 2024.09.10 |



